- Hochschule Trier
- Campus wählen
- Quicklinks
-
- English
Der Begriff Blind-Source-Separation (BSS) beschreibt einen Prozess zur Trennung von vermischten Signalen in einem beliebigen System. Die Herausforderung besteht darin, dass keine Kenntnisse über das Mischsystem oder die Quellsignale selbst vorhanden sind. BSS wird in zahlreichen unterschiedlichen Domänen angewandt, darunter Medizin (z. B. Extraktion relevanter Gehirnströme aus Messreihen), Wirtschaft (Vorhersage von Aktienverläufen), Sprach- und Bilderkennung. Im folgenden Versuch wird die BSS am Beispiel des Cocktailpartyproblems demonstriert. Hierzu wird die Unabhängigkeitsanalyse (Independent Component Analysis – ICA) als Verfahren eingesetzt.
Das Cocktailpartyproblem verdankt seinen Namen dem Umstand, dass man es mit der Analogie einer Party sehr gut auf den Punkt bringen kann. Man stelle sich viele Gäste auf einer Party vor, welche dicht beieinander stehen. Vorausgesetzt die Musik ist nicht allzu laut, kann ein gesunder Mensch die Stimme seines Gesprächspartners im Allgemeinen von den anderen Geräuschen trennen und ihn so verstehen. Dies soll nun maschinell gelöst werden, allerdings in erweiterter Form: Es soll nicht nur eine Stimme herausgefiltert werden, sondern alle Redner sollen voneinander separiert werden. Es existieren also einige Signalquellen, deren Ausgangssignale s von einer bestimmten Anzahl an Empfängern (Mikrofonen, in der Partyanalogie zwei Ohren) aufgenommen werden, wobei die Empfänger durch ihre unterschiedlichen Standorte und eventueller Hindernisse die Quellsignale in unterschiedlichen Abmischungen empfangen. In Innenräumen entstehen dabei Echos durch Reflexionen. Die einzigen zur Verfügung stehenden Eingaben in den Algorithmus sind die empfangenen Mischsignale x, es gibt kein Vorwissen über die Standorte der Signalquellen und -empfänger oder die Inhalte der Signale selbst. Um das Problem zu lösen, wenden wir eine Pipeline verschiedener Verarbeitungsschritte an, von denen der Kern eine ICA (Independent Component Analysis) darstellt.
Eine der wichtigsten Eigenschaften zur Beschreibung und Unterscheidung von verschiedenen BSS-Systemen ist das Verhältnis von der Anzahl der Quellsignale s und der empfangenen Mischsignale w. Im Rahmen des Cocktailpartyproblems entspricht dies der Anzahl der Schallquellen und der Anzahl der Mikrofone respektive deren Aufnahmen. Wenn die Anzahl der Quellen und Mikrofone gleich ist, wird das System als „bestimmt“ bezeichnet. Wenn die Anzahl der Quellen geringer ist als die Anzahl der Beobachtungen, wird der Fall als „überbestimmt“ bezeichnet und in der Regel dadurch gelöst, dass das Problem auf den bestimmten Fall reduziert wird. Übersteigt jedoch die Anzahl der Quellen die Anzahl der Beobachtungen, so spricht man von einem Szenario, das „unterbestimmt“ genannt wird, was den schwierigsten Fall darstellt. Eine andere wichtige Eigenschaft von BSS-Systemen ist das herangezogene Mischmodell, mit dem abgebildet wird, wie die Quellsignale sich zu den empfangenen Signalen vermischen.
Lineares Mischmodell
Nicht ohne Grund erinnert die obige Nomenklatur an die Lösung linearer Gleichungssysteme, denn genau darauf läuft es beim linearen Mischmodell auch hinaus. Eine lineare Mischung der Quellsignale s1(t),s2(t),...,sN(t) produziert danach die Mischsignale x1(t), x2(t),..., xM(t) nach den folgenden Regeln:

Dabei sind aij die Mischungskoeffizienten, welche in Matrixform geschrieben die Mischmatrix A ergeben. Wenn man s und x ebenfalls zu Matrizen der Form
S(t) = [s1(t), s2(t),...,sN(t)]Tund X(t) = [x1(t), x2(t),...,xM(t)]T fasst, entspricht der Mischprozess der Gleichung X(n) = AS(n)
Das Ziel ist, zu dieser sog. Transformationsmatrix A, welche im realen Anwendungsfall unbekannt ist, eine möglichst gute Annäherung an die Inverse W≈ A-1 zu ermitteln und mit ihrer Hilfe ein Y(t)≈ X(t) nach der Gleichung y(t) = Wx(t) zu errechnen. Diese Berechnungen sind unter zwei Annahmen möglich: A ist quadratisch (das System ist also bestimmt) und hat vollen Rang (keine linearen Abhängigkeiten, die Quellsignale sind also unabhängig voneinander).
Das lineare Modell ist eine gute Annäherung an Echtweltszenarien, wenn es keine Einflüsse durch Reflexionen gibt und zwischen Signalquellen und -empfängern direkte Sichtverbindung besteht — also hauptsächlich Outdoor-Szenarien. Um Indoor-Szenarien abzubilden, wird das mächtigere Faltungsmodell bemüht.

Faltungsmischmodell
Bei der Betrachtung von Innenräumen kommt es häufig vor, dass aufgrund der Reflexionen in einem Raum mehrere verzögerte Varianten der Quellsignale an den Empfängern ankommen. Um ein solches System zu beschreiben, ist ein Mischmodell realistischer, welches auf den Prozess der Signalfaltung aufbaut. Das Faltungsmodell arbeitet nicht durch ein lineares Gleichungssystem, sondern mit der linearen Faltungsoperation: (f * g)(t) = ∫ f(π)g(t-π)dπ
Die Faltung ist ein geeignetes Modell für viele physikalische Prozesse, die bestimmte Eigenschaften teilen. Passenderweise hat auch die Ausbreitung von Schall in einem Raum diese Eigenschaften. Setzt man für f ein Quellsignal s und für g eine sog. Raumimpulsantwort (RIR), so ist das Ergebnis s*g eine abgewandelte Version von s, nämlich ergänzt um die Ausbreitungseigenschaften des Schalls im Raum. Diese Information ist in g enthalten.
Die Raumimpulsantwort besteht aus einem starken, kurzen Impuls, der möglichst alle Frequenzen abdeckt (in der Audiopraxis oft aufgenommen durch das Zerplatzen eines Luftballons). Stellt man ein Mikrofon in einem Raum an Position a auf und lässt dann einen Luftballon an einer anderen Position b im Raum platzen, enthält der aufgenommene Knall die Echos und andere Verzerrungen des Signals, die in dieser Standortkombination (a,b)von Geräuschquelle und Mikrofon auftreten. Durch die Faltung eines Audiosignals (z. B. eines Musikstücks) und einer Raumimpulswort (z. B. aufgenommen in einer Kirche an Position a) wird das Ergebnis s*g klingen, als wenn das Musikstück in dieser Kirche an Position b abgespielt und der Klang mit besagten Mikrofon an Position a wieder aufgenommen würde. Alle erzeugten Echos sind dann darin enthalten.
Im diskreten Fall (wenn f und g also diskrete Abstufungen haben, was bei unserem Versuch durch die Abtastrate der Mikrofone gegeben ist), lässt sich der Faltungsprozess vereinfacht darstellen als

mit L als Länge der Raumimpulsantwort in Abtastungen, also z. B. 8000Hz * 0.3s = 2400 bei einer Länge von 0.3s mit der Abtastrate 8kHz.
Ein Faltungsprozess beschreibt hier also die konkrete Veränderung eines Quellsignals sj auf dem Weg vom Sender j zum Empfänger i. Um die Mischsignale der Empfänger zu erhalten, werden die Faltungen aller Quellsignale zu diesem Empfänger aufsummiert. Die Mischsignale xi(t) ergeben sich demnach für alle i Empfänger durch

wobei N die Anzahl der Quellsignale und hij die Raumimpulsantwort von Signalquelle j zu Empfänger i ist.

Definiert man die Matrix H(n) als Sequenz von Matrizen, die alle Raumimpulsantworten enthalten, so ist das konvolute Mischmodell durch die Gleichung x(t) = [H(n)]*s(n) beschrieben.
Zur Durchführung der Übungen wird lediglich ein Computer mit der Software MATLAB benötigt, da Sprachaufnahmen bereits mitgeliefert werden. Diese werden dann im Laufe der Übung rechnerisch vermischt und anschließend mithilfe der vorgestellten Pipeline wieder getrennt. Diese Vorgehensweise erlaubt eine Quantifizierung der Güte des Verfahrens, da die wiederhergestellten Signale mit den vorliegenden Quellsignalen verglichen werden können, ohne eine Verfälschung durch Rauschen oder andere Störfaktoren zu riskieren.
Allerdings können die Skripte gleichsam dazu verwendet werden, selbst aufgenommene Audiodateien zu trennen. Hierzu benötigt man bestenfalls baugleiche Mikrofone in der gleichen Anzahl wie zu trennende Signalquellen. Bei der Aufnahme ist darauf zu achten, dass mittels eines kurzen Impulses (z. B. Händeklatschen) ein Zeitstempel gesetzt wird. Alle Aufnahmen müssen so geschnitten sein, dass die zeitlich parallel ablaufen (also der Impuls in allen Dateien nach der gleichen Zeit ertönt). Die Einspeisung versetzt aufgenommener Signale wird das Ergebnis erheblich verschlechtern, eine automatische Korrektur ist in diesem Versuch nicht vorgesehen.
Des Weiteren muss sichergestellt werden, dass alle Aufnahmen in derselben Abtastrate erstellt werden.
Erzeugung der Mischsignale
Zunächst erzeugen wir für den simulierten Versuch im Computer die Signale xM(t) nach der Formel wie x(t) = [H(n)]*s(n) wie beschrieben im Abschnitt Faltungsmischmodell. Wir haben somit N=2 Quellsignale und M=2 „aufgenommene“ Mischsignale, welche nach den N Transformationsmatrizen in [H(n)] erzeugt wurden.
Doch aus verschiedenen, unten beschriebenen Gründen, nutzen wir diese Mischsignale nicht direkt als Input für ICA, sondern bereiten sie zunächst vor.
Fourier-Transformation (FFT)
Jedes beliebige periodische Signal x lässt sich auf zwei verschiedene, aber vom Informationsgehalt her gleichwertige Weisen mathematisch darstellen. Zunächst als Funktion der Amplitudenausschläge in Abhängigkeit von der Zeit, wie bisher gegeben. Diese Funktion wird bezeichnet mit x(t). Allerdings lässt sich jedes periodische Signal auch zerlegen in seine einzelnen Bestandteile, denn es besteht aus einer Überlagerung von sinusoiden Signalen unterschiedlicher Amplitude (Stärke) und Phase (Verschiebung). Jedes (auch nicht-sinusoide) periodische Signal kann also angenähert werden durch eine solche Überlagerung von sinusoiden Signalen, und je mehr sinusoide Signale in die Überlagerung einfließen, desto besser kann das darzustellende Signal angenähert werden.
Anstatt das Signal x(t) also über die Amplitudenausschläge in Abhängigkeit der Zeit darzustellen (wie gewöhnlich), kann man sich also auch vorstellen, dass x(t) nicht endlich wäre, sondern sich immer wiederholen würde (also periodisch wäre). Dann kann man oben stehende Eigenschaft periodischer Signale ausnutzen und x(t) stattdessen anhand seiner sinusoiden Bestandteile darstellen. Diese Darstellung schreibt sich X(f). f ist die Frequenz des betrachteten Bestandteils und X(f) beschreibt das zugehörige sinusoide Teilsignal anhand seiner Amplitude (Stärke) und Phase (Verschiebung). Da dies zwei Informationen sind, wird X(f) oft als komplexe Zahl dargestellt, um beide Informationen mithilfe des reellen und imaginären Teils codieren zu können.
In der Zeitdomäne x(t) war es die Abtastrate, die bestimmte, wie genau das Ausgangssignal abgebildet werden konnte. In der Frequenzdomäne X(f) wird dies nun durch die Anzahl der betrachteten Frequenzen bestimmt.
Die mathematische Operation, welche diese Aufspaltung eines periodischen Zeitsignals in seine Frequenzbestandteile durchführt, nennt sich Fourier-Transformation. Wir führen vor der Ausführung von ICA eine solche Fourier-Transformation durch, da bei der direkten Anwendung von ICA auf die Zeitsignale ein unangenehmer Nebeneffekt von ICA auftreten würde: Zeitliche Verzögerungen, welche durch die Raumimpulsantwort entstehen, würden verworfen werden, was den Separierungsprozess insgesamt verschlechtern würde. Diese Eigenschaft wird durch die ersatzweise Anwendung auf der Frequenzdomäne vermieden.
Die Formel für die Fourier-Transformation einer integrierbaren Funktion x ∈ L1(ℝn) mit Argument t lautet:

STFT als Spezialfall der FFT
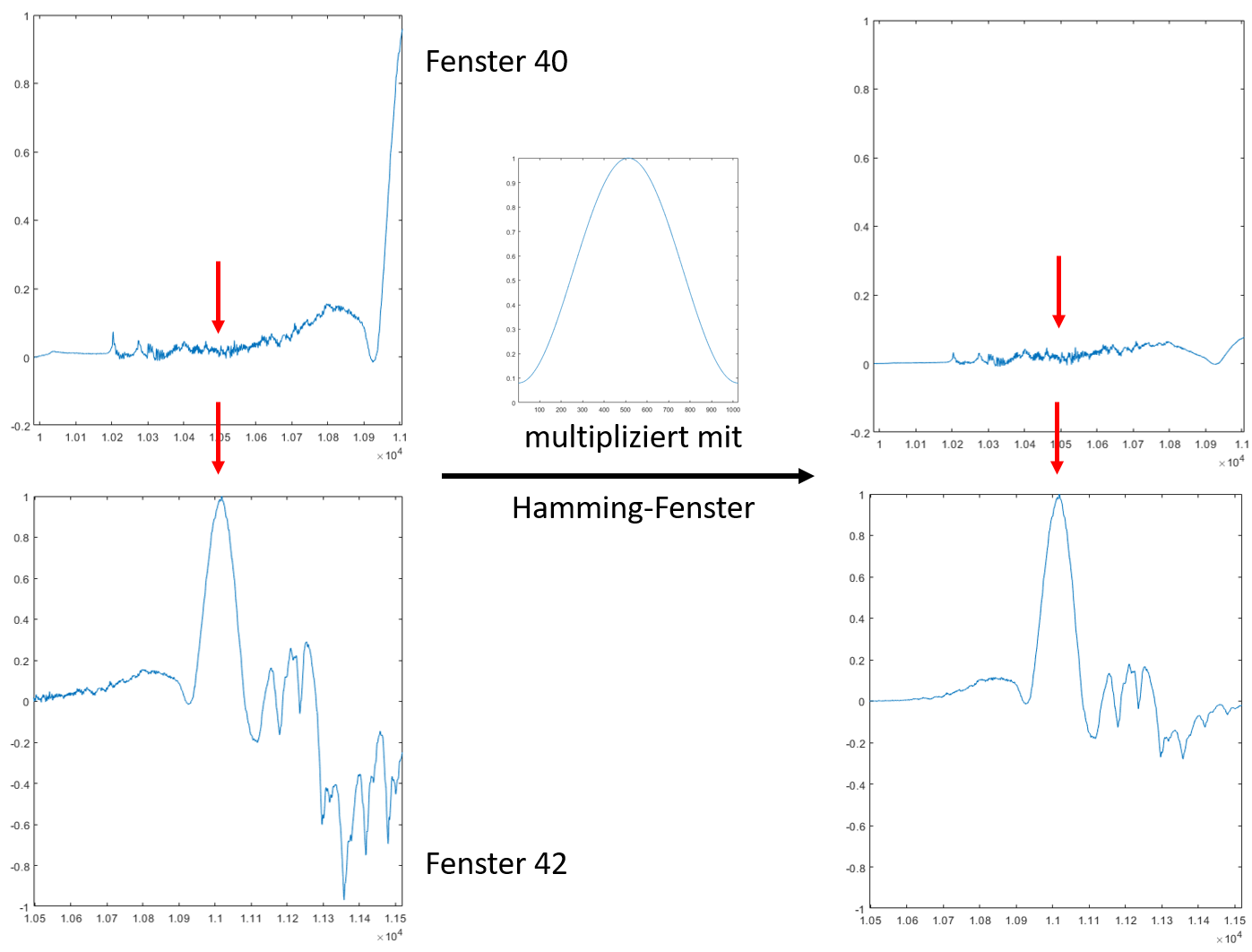
Um die Ergebnisse von ICA insgesamt zu verbessern, wird allerdings nicht eine einzige Fourier-Transformation über die gesamte Signallänge xi(t),0 < i < M durchgeführt, sondern die Signale werden in mehrere kleine, sich überlappende Zeitfenster zerschnitten. Um die Periodizität der Signale zu verbessern, werden die Fenster jeweils mit einer Fensterfunktion multipliziert, welche in der Mitte den Wert 1 hat und an den Seiten nahe zur 0 kommt, beispielsweise das Hamming-Fenster. So fallen die Signale in den Fenstern seitlich jeweils zu 0 ab, der relevante Teil ist nur in der Mitte. (siehe Abbilung rechts)
Seien lenx die Länge eines Signals und lenw die Länge eines Fensters in Abtastungen sowie hopw die Länge der Sprünge zwischen den Fenstern in Abtastungen, so ergibt sich die Anzahl der resultierenden Fenster zu AnzFensterProSignal =⎡(lenx - lenw) / hopw⎤
Bei M aufgenommenen Signalen erhält man also für jedes dieser Signale die oben errechnete Anzahl Fenster. Für jedes Signal entstehen gleich viele Fenster. Jedes dieser Fenster wird nun fourier-transformiert. Durch die vorige Multiplikation mit dem Hamming-Fenster haben nur noch die jeweils in der Mitte eines Fensters liegenden Zeitwerte (in Abbildung rot markiert) signifikante Auswirkungen auf die Foruiertransformierte.
Die Genauigkeit der Umwandlung, also die Länge der Fouriertransformierten lenf f t kann im Skript eingestellt werden. Da die Frequenzen später anhand bestimmter Eigenschaften der Audiosignale in einem binären Baum einsortiert werden, sollte dieser Wert als Potenz von 2 gewählt werden. Die f f t enthalten allerdings aus rein mathematischen Gründen die Informationen für jede Frequenz doppelt (im positiven wie im negativen Bereich, an der Y-Achse gespiegelt). Eine f f t der Länge lenf f t enthält also tatsächlich die Informationen zu AnzFreqs = ⎡(lenf f t)/2⎤ Frequenzen, mit fmin = 0Hz und fmax = 1/2 Abstastrate, der höchstmöglichen Frequenz laut Nyquist-Theorem.
Einteilung der Daten in Frequenz-Bins
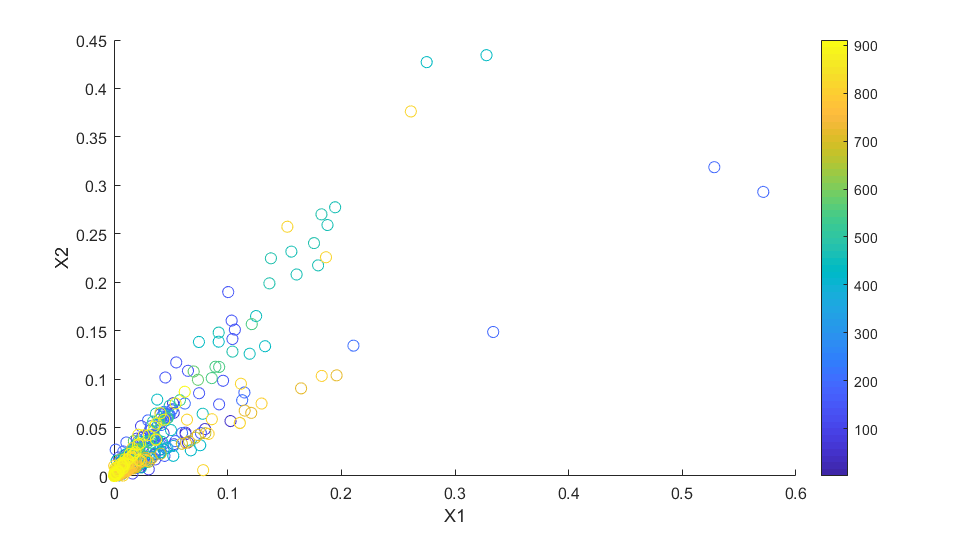
Wir betrachten die Daten nun getrennt nach den einzelnen AnzFreqs Frequenzen. Nehmen wir zur Erklärung eine beliebige Frequenz fj an, die in der FFT enthalten ist. Jedes Fenster enthält die Information, wie sehr fj das Signal im jeweiligen Signalausschnitt beeinflusst hat (Amplitude). Wir betrachten nun für jedes der M Signale das erste Fenster und stellen die Amplituden von Frequenz fj in diesem Fenster einander gegenüber. Dies tun wir auch für die jeweils zweiten Fenster und alle weiteren zeitlich zueinander gehörenden Fenster. Das Resultat lässt sich jeweils in einem Streudiagramm wie Abbildung 6 darstellen. Eine solche Darstellung existiert für alle AnzFreqs Frequenzen. Jede solche Anordnung bezeichnen wir als „Frequenz-Bin“ und führen die weiteren Vorverarbeitungsschritte (Zentrierung, Whitening) sowie FastICA getrennt für jeden Frequenz-Bin einzeln aus. Beispielhafte Darstellung eines Frequenz-Bins für f = 1000Hz in einem Szenario mit M=2 Empfängern und AnzFensterProSignal = 911 (farblich markiert). Der rechteste Punkt sagt beispielsweise, dass für das 199. Fenster (Farbe) von X1 (horizontale Achse) der Amplitudenausschlag 0.57 und von X2 (vertikale Achse) der Amplitudenausschlag 0.29 beträgt. Diese Darstellung existiert nicht nur für f = 1000Hz, sondern auch für alle anderen von der FFT dargestellten Frequenzen.
Zentrierung und Whitening
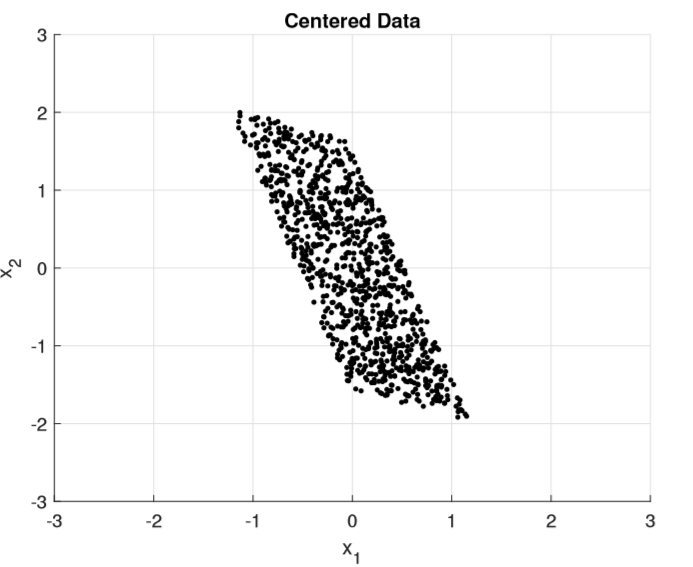
Im Folgenden wird der Anschaulichkeit halber der folgende Plot eines Vektors zweidimensionaler nicht-gauß’sch verteiler Zufallsvariablen als beispielhafter Frequenz-Bin der Quellsignale angenommen, anhand dessen die nachfolgenden Transformationen erklärt werden.
Vor der Übergabe in die ICA werden die Daten der Frequenzbins noch durch die Vorverarbeitungsschritte Zentrierung und Whitening geführt. Beide Schritte sind optional, verbessern aber die Laufzeit der anschließenden ICA, wenn vorher durchgeführt. Zentrierung bedeutet nichts anderes als die Subtraktion des Mittelwerts der einzelnen Komponenten m = E(x), sodass die Daten um den Nullpunkt zentriert sind.
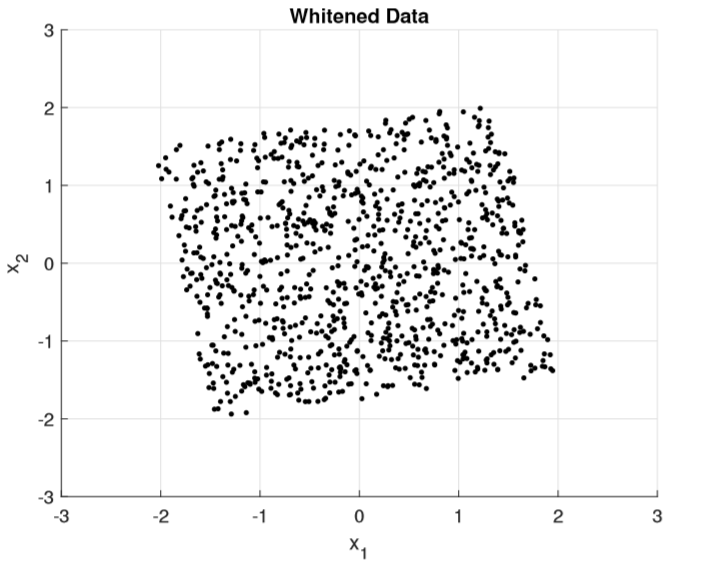
Beim Whitening werden die Daten derart linear transformiert, dass die Komponenten dekorreliert sind und eine einheitliche Varianz von 1 haben, hierzu wird eine Eigenwertzerlegung auf die Daten angewandt. Durch die Herstellung einer einheitlichen Varianz zwischen den Komponenten wird erreicht, dass alle Komponenten von ICA gleichwertig behandelt werden.
Durch diese vorgezogene lineare Transformation verändert sich die von der ICA zu findende Mischmatrix, denn die gesamte Transformation ergibt sich nun zu x~ = WAs = As, wobei W die Transformation durch Whitening beschreibt und A die ursprüngliche Mischmatrix. Die nun zu findende Matrix A~ ist nun allerdings orthogonal. Das ist ein Vorteil, da sich dadurch die Freiheitsgrade reduzieren und ICA schneller zum Ziel kommt.
Nach der Aufsplittung der aufgenommenen Signale in Zeitfenster, der Umwandlung dieser Fenster in den Frequenzbereich und der Anwendung von Vorverarbeitungsschritten (Zentrierung, Whitening) wird nun die eigentlich Unabhängigkeitsanalyse vollzogen, um die ursprünglichen Quellsignale wieder anzunähern. Doch wieso soll das mit ICA funktionieren?
Das Ziel von ICA besteht darin, ein multivariates Signal in mehrere unabhängige Signale mit nicht-gauß'scher Verteilung zu zerlegen, welche, wenn aufaddiert, das multivariate Signal ergeben. Aus mehreren Gründen spielt das gerade im Anwendungsfall der BSS in die Hände:
ICA nimmt die Mischsignale entgegen und strebt sie so zu zerlegen, dass die Verteilung der unabhängigen Zerlegungen maximal nicht-gauß’sch ist. Nach den Annahmen unseres Modells sind die erreichten Zerlegungen Kandidanten für die Quellsignale.
Um die Eigenschaft der Zerlegungen als nicht-gauß’sch verteilt zu quantifizieren, wird ein Zielmaß benötigt, welches aus dem Englischen Nongaussianity genannt wird. ICA ist ein iterativer Optimierungsalgorithmus, der ein Maß für die Nongaussianity maximiert, bis ein Abbruchkriterium erreicht ist (Zerlegungen ähneln sich sehr stark oder maximale Anzahl an Iterationen erreicht). Als Maß für die Nongaussianity eignen sich etwa die Wölbung oder die Negentropie, die vereinfacht als Kehrwert der aus der Informationstheorie bekannten Entropie betrachtet werden kann.
Die Kostenfunktionen lauten:
Im Versuch wird die ICA-Implementierung FastICS verwendet, entwickelt von Hyvärinen. Der Algorithmus wird verkürzt in der Abbildung dargestellt. Nach Anwendung von FastICA sieht der wiederhergestellte Frequenz-Bin wie unten dargestellt aus. Die Form entspricht den Originaldaten aus ssample jedoch kann die Skalierung nicht wiederhergestellt werden (deswegen folgt noch die Skalierungskorrektur). Des Weiteren können auch die Achsen vertauscht sein (deswegen folgt noch die Permutationsausrichtung).



Permutationsausrichtung
Vor Durchführung der ICA hat man eine Vielzahl an Frequenz-Bins, welche durch ICA getrennt voneinander in ihre unabhängigen Komponenten zerlegt werden. Diese Komponenten entsprechen den wiederhergestellten Quellsignalen y. Die Reihenfolge dieser unabhängigen Komponenten wird nun aber durch jede ICA unabhängig von den anderen Frequenz-Bins vergeben und so kann es sein, dass beispielsweise die durch die ICA zu Frequenz-Bin 1 entstandene erste unabhängige Komponente y1f1 zu s1 gehört und y2f1zu s2, aber bei der ICA zu Frequenz-Bin 2 entsteht y1f2 so, dass es zu s2 gehört und y2f2zu s1. Oder um es auch für jeden Fall N>2 allgemein auszudrücken: Die Reihenfolge der unabhängigen Komponenten ist durch jede ICA für jedes Frequenz-Bin beliebig vertauscht, also permutiert. Bildlich gesprochen: Die Achsen der obigen Abbildung sind für jeden Frequenz-Bin anders vertauscht. Würden die Frequenz-Bins so wieder zusammengeführt werden, wären die Frequenzbestandteile der resultierenden Signale wild gemischt. Deshalb müssen alle Frequenz-Bins gleich ausgerichtet werden, sodass yifi zu si gehört für alle 1 ⩽ i ⩽ AnzSignale und 1 ⩽ j ⩽ AnzFreqs.
Dies erledigt die Permutationsausrichtung, umgesetzt durch den Algorithmus \textit{Dyadic Sorting}. Dieser nutzt den Umstand aus, dass zwischen zwei direkt benachbarten Frequenzen große statistische Zusammenhänge bestehen. Voraussetzung ist, dass AnzFreqs= 2n , n ∈ N. Anfangs wird für jedes Frequenz-Bin eine Permutationsmatrix ∏f = I ∀ f erstellt. Dyadic Sorting vergleicht nun je zwei benachbarte Frequenz-Bins (f1 wird mit f2 verglichen, f3 mit f4 usw.) und berechnet diejenige Permutation für die Komponenten, welche die Korrelation der Komponenten zwischen den verglichenen Frequenz-Bins maximiert. Die Permutationsmatrizen werden dann entsprechend angepasst. Die Betrachtung der genauen Berechnung der Korrelation würde an dieser Stelle zu weit führen. Das Ergebnis der Berechnung ist jedenfalls, dass für die verglichenen Bins die Komponenten der Signale derart vertauscht werden, dass obige Bedingung (yifi gehört zu si) höchstwahrscheinlich erfüllt ist innerhalb der jeweils verglichenen Bins.
Anschließend werden die verglichenen Bins zu je einer Gruppe mit zwei Bins zusammengefasst. Die Gruppen gelten intern als sortiert und die Berechnung wiederholt sich zwischen den neuen benachbarten Gruppen. Dies wiederholt sich, bis nur noch eine Gruppe existiert, welche intern sortiert ist. Es entsteht also ein binärer Baum. Der Algorithmus ist am Ende, wenn der binäre Baum an der Wurzel angelangt ist. Die Komponenten sind dann für alle Frequenz-Bins derart vertauscht, dass obige Bedingung (yifi gehört zu si für alle 1 ⩽ i ⩽ AnzSignale und 1 ⩽ j ⩽ AnzFreqs.) erfüllt ist.
Die finalen Permutationsmatrizen ∏f aller Frequenz-Bins werden schließlich mit den zugehörigen Wiederherstellungsmatrizen W(f) multipliziert, um die Vertauschung letztlich anzuwenden.
Skalierungskorrektur
Die Signale, die durch den ICA-Algorithmus zerlegt sind, können durch eine beliebige Konstante im Vergleich zum Originalsignal skaliert sein. Während dieser Effekt bei unmittelbarer Anwendung von ICA im, Zeitbereich nicht sehr groß ist, wird er bei der Betrachtung im Frequenzbereich relevant. Ohne Skalierungskorrektur könnte dieser Umstand dazu führen, dass Frequenzkomponenten unterschiedlich gedämpft werden und somit ein verzerrtes Audiosignal entsteht.
Im Falle eines bestimmten Systems von NxN Quellen und Mikrofonen lässt sich die Skalierungsunschärfe von ICA recht einfach korrigieren. Das von Kiyotoshi Matsuoka erarbeitete Minimal Distortion Principle besagt, dass jedes Mikrofonsignal Xi nur minimal von dem Separierungsprozess beeinflusst werden sollte, der zu dem geschätzten Quellsignal Yi für i ∈ {1,..., N} führt. Diese Methode ist untenstehend implementiert, wobei Wp(f) die Wiederherstellungsmatrizen nach der Ausrichtung der Permutation bezeichnet.
Ws(f) = diag( W-1p (f) ) Wp(f)
Zunächst wird eine inverse STFT auf die einzelnen Fenster angewandt, um sie in den Zeitbereich zurückzutransformieren. Anschließend werden die einzelnen Fenster der Signale jeweils an ihrer zugehörigen Stelle im Zeitsignal aufaddiert. Das Ergebnis sind jeweils die wiederhergestellten Signale yi,1 < i < M wobei die Reihenfolge der ursprünglich zur Simulation verwendeten Quellsignale s dem System natürlich unbekannt ist.
Das Problem der Blind Source Separation, gängig formuliert als das Cocktailpartyproblem, zeigt eindrucksvoll die Möglichkeiten der Verwendung von statistischen Verfahren zum Lösen wissenschafts- und alltagsrelevanter Fragestellungen. Die Möglichkeit, trotz der starken Beschränkung des Wissens auf die Quellsignale rückzuschließen, ist so faszinierend wie das dahinterstehende Verfahren komplex und vielschichtig ist.
Das vorgestellte Verfahren kann je nach Anwendungsgebiet variiert und erweitert werden. Eine Möglichkeit dazu stellt der Einbau von Beamforming-Algorithmen dar, um durch den Einsatz von Mikrofon-Arrays und Interpolation auf die räumliche Position einer Signalquelle zu schließen und nur Signale aus bestimmten Richtungen zu filtern.
Sie verlassen die offizielle Website der Hochschule Trier