- Hochschule Trier
- Campus wählen
- Quicklinks
-
- English
Rekurrente Neuronale Netzwerke (RNN) haben in den vergangenen Jahren eindrucksvolle Ergebnisse im Bereich der Verarbeitung natürlicher Sprache (NLP) erzielt, z.B. zum Zweck der Spracherkennung oder der automatischen Übersetzung. Zudem wurden RNN auch mit Erfolg im Bereich des Maschinellen Sehens eingesetzt, z.B. um automatisch textuelle Beschreibungen für Bilder zu generieren. Dieser Versuch bietet eine Einführung in diese äußerst leistungsstarke Methode des Maschinellen Lernens. Dabei werden bei der Konstruktion eines Shakespeare-Sprachmodells und bei der Erstellung eines Modells zur automatischen Generierung von Bildbeschreibungen praktische Erfahrungen gesammelt.
In diesem Versuch beschäftigen wir uns mit der Sequenzerkennung mit Hilfe Rekurrenter Neuronaler Netze (RNN). Um ein tiefgehenderes Verständnis von dem Algorithmus zur Fehlerrückpropagierung durch die Zeit zu erhalten, werden wir zunächst eine vereinfachte Version ohne TensorFlow implementieren. Anschließend werden wir häufig beim Training von RNN auftretende Probleme analysieren und verschiedene Wege erforschen, um diesen zu begegnen. Als Nächstes wollen wir die grundlegende RNN-Architektur in TensorFlow sowie die Erweiterung zum Long Short-Term Memory (LSTM) betrachten. Als Erstes werden wir diese Modelle für stark vereinfachte Aufgaben einsetzen, in denen eine Zeitreihe fortgesetzt werden soll, z.B. um eine Sinuskurve zu extrapolieren oder um die Eingabe zu memorieren. Im Anschluss daran betrachten wir die Sprachmodellierung, d.h. die Vorhersage des nächsten Wortes in einem Satz mit Hilfe von RNN. Abschließend werden wir ein Modell trainieren, das für ein Eingabebild automatisch eine textuelle Beschreibung erzeugen soll.
Wir werden für diesen Versuch erneut TensorFlow verwenden (eine kurze Anleitung zum Einrichten findet sich in Versuch 6). Bevor wir damit beginnen, wollen wir ein sehr einfaches RNN nur unter Nutzung von numpy konstruieren, um den Algorithmus zur Fehlerrückpropagierung durch die Zeit besser zu verstehen.
Dieser Versuch umfasst die folgenden Inhalte:
Im ersten Teil des Versuchs geht es darum, ein vereinfachtes RNN nur mit Hilfe von numpy zu implementieren. Hier arbeiten wir mit zufällig generierten Sequenzen als Eingabe für das Netzwerk. Das Netzwerk soll diese Zufallssequenz memorieren. Die Datei q1_bptt/data_generator.py enthält bereits eine Implementierung für die Generierung der Daten. Der zweite Teil des Versuchs verwendet TensorFlow als Grundlage. Wir werden in diesem Teil mit verschiedenen Datensätzen arbeiten. Die erste Aufgabe ist die Memorierung von Zufallsdaten, ähnlich wie zuvor. Die Handhabung dieses Datensatzes ist bereits in der Funktion generate_batch_memory_task in q2_rnn/data_generator.py implementiert. Darüber hinaus werden wir Sinuskurven mit zufälliger Frequenz und Phasenverschiebung generieren. Dies ist in der gleichen Datei in der Funktion generate_sin_data implementiert. Der nächste Datensatz verwendet Texte von Shakespeare als Grundlage. Hierfür ist die Funktion generate_shakespeare_data bereits implementiert, die den Datensatz einliest. Die Textdatei shakespeare.txt wird neben dem Quelltext ebenfalls als Download zur Verfügung gestellt.

Rekurrente Neuronale Netze (RNN) sind eine Erweiterung von sog. Feed-Forward-Netzen (MLP), die als Eingabe statt einem einzelnen Vektor eine Sequenz von Daten erhalten. RNN fügen der Netzwerkstruktur rekurrente Verbindungen hinzu, durch welche der interne Zustand als zusätzliche Eingabe für den nächsten Zeitschritt verwendet wird. Die Netzwerkparameter eines RNN sind unabhängig von der Zeit, d.h. es gibt nur einen Satz an Parametern. RNN können auf beliebig lange Eingabesequenzen angewendet werden. Die Abbildung unten zeigt ein einfaches RNN, das über die Zeit abgewickelt wurde. Hier ist zu sehen, dass die rekurrente Gewichtsmatrix Whh unabhängig vom Zeitpunkt ist. Die versteckte Aktivierung ht zu Zeitpunkt t kann wie folgt berechnet werden:
Um die Aktivierungen für alle Zeitschritte zu berechnen, initialisieren wir zunächst den initialen internen Zustand h0, der entweder gelernt oder wie in der Abbildung auf 0 gesetzt werden kann. Im Anschluss wird die obige Gleichung für jeden Zeitschritt angewandt.
Üblicherweise werden über einem solchen rekurrenten Layer entweder noch weitere rekurrente Layer angeordnet oder es wird ein finales lineares Ausgabe-Layer am Ende angebracht.

Um den Gradienten der Kostenfunktion in Bezug auf die Netzwerkparameter des RNN zu berechnen, wird die Fehlerrückpropagierung erweitert zur Fehlerrückpropagierung durch die Zeit (Backpropagation Through Time, BPTT). Auch hier wird TensorFlow in der Praxis die Berechnung der Ableitungen übernehmen, sodass wir hier nur kurz die zugrunde liegende Idee beleuchten. Wir betrachten Hidden Layer h aus Abbildung RNN und setzen eine Kostenfunktion $E$ voraus, die sich aus den einzelnen Kosten aus jedem Zeitschritt zusammensetzt, d.h. E = ∑Tt=1Et. Ausgehend vom Ausgabelayer können wir nun die Gradienten ∂Et / ∂ht für jeden Zeitschritt herleiten (wie in der Abbildung gezeigt). Als Nächstes wollen wir die Gradienten in Bezug auf den darunterliegenden Layer betrachten. Um das Berechnungsergebnis eines RNN zu erhalten, nutzen wir die Gleichung ht vorwärts durch die Zeit. Bei der Fehlerrückpropagierung müssen wir rückwärts durch die Zeit gehen, um die Gradienten zu propagieren. Hier wollen wir das Beispiel aus der Abbildung mit 3 Zeitschritten betrachten. Weil h1 und h2 zeitlich früher gelegen sind als h3, haben ihre Gradienten keinen Einfluss auf den Gradienten für h3. Aus diesem Grund können wir wie folgt beginnen:
Wie wir gerade gesehen haben, multiplizieren wir in jedem Schritt des Fehlerrückpropagierungsalgorithmus durch die Zeit mit der transponierten rekurrenten Gewichtsmatrix Whh. Wenn wir dies für viele Zeitschritte machen, potenzieren wir diese Matrix mit einem hohen Exponent. Basierend auf der Analyse der Eigenwerte von Whh kann man feststellen, dass die Gradienten über Zeit entweder exponentiell explodieren oder verschwinden, was ein Problem in der Praxis darstellt. Eine Möglichkeit, den explodierenden Gradienten zu begegnen, ist die Gradientenlimitierung (Gradient Clipping), die im Aufgabenblatt beschrieben ist. Das Problem der verschwindenden Gradienten kann u.A. durch eine wie im Folgenden beschriebene komplexere RNN-Architektur angegangen werden.
Die Long Short-Term Memory (LSTM)-Architektur erweitert das einfache RNN um einen versteckten Zellenzustand (zusätzlich zum internen Zustand) sowie um mehrere multiplikative Gatter. Der interne Zellenzustand wird zu jedem Zeitschritt unter Verwendung eines Eingabe- und eines Vergessens-Gatter neu gesetzt, die entscheiden, wieviel Einfluss die Eingabe und der vorherige versteckte Zellenzustand auf den aktuellen Zustand haben sollen. Zudem wird die Ausgabe aus einer LSTM-Zelle durch ein Ausgabegatter geregelt. Die LSTM-Architektur ermöglicht es dem Netzwerk, viel besser mit langen Sequenzen umzugehen und verringert den negativen Einfluss verschwindender oder explodierender Gradienten.
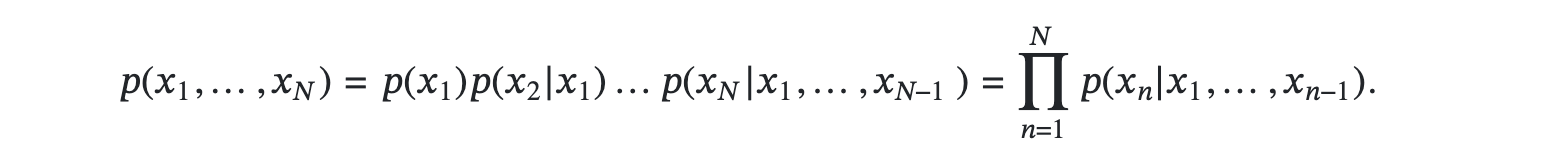
Die Sprachmodellierung ist eine zentrale Aufgabe in der Verarbeitung natürlicher Sprache (NLP) und ermöglicht viele wichtige Anwendungen wie Spracherkennung oder maschinelle Übersetzung. Ein Sprachmodell weist jeder möglichen Sequenz von Wörtern eine Wahrscheinlichkeit zu. Für eine Sequenz x1, ... , xN von N Wörtern verwendet ein typisches Sprachmodell die rechts dargestellte Faktorisierung.
Dies bedeutet, dass Sprachmodelle in der Regel nur lernen müssen, eine Vorhersage über das nächstfolgende Wort treffen zu müssen.
In der Praxis müssen Sprachmodelle mit großen Wortschätzen arbeiten, was die Aufgabe für normale neuronale Netze schwierig macht. Häufig wird ein sog. Embedding gelernt, welches dem im One-Hot-Format vorliegende Eingabewort (ein Vektor in der Länge des gesamten Vokabulars, der eine 1 an der Komponente für das entsprechende Wort hat und eine 0 für alle anderen Wörter) einen dicht besetzten Embedding-Vektor zuweist, der das Wort repräsentiert. Statt eine große Gewichtsmatrix mit dem dünn besetzten One-Hot-Eingabevektor zu multiplizieren, reicht es, einfach die betreffende Spalte der Gewichtsmatrix auszulesen, ohne die Multiplikation auszuführen.
Implementierung der Fehlerrückpropagierung durch die Zeit
Als erste Aufgabe wollen wir den Algorithmus zur Fehlerrückpropagierung durch die Zeit für ein simples RNN direkt mit numpy, d.h. ohne TensorFlow, implementieren. Dazu muss zunächst die BasicRNNCell.fprop-Funktion implementiert werden, die die Vorwärtsrichtung berechnet und anschließend die BasicRNNCell.bprop-Funktion, die den Rückweg berechnet. Um die Aufgabe etwas zu erleichtern, sind auf dem Aufgabenblatt die genauen Gleichungen aufgeführt, die implementiert werden müssen. Zur Prüfung der Korrektheit der Implementierung kann die run_check_grads-Funktion verwendet werden, die das Ergebnis der Gradienten-Berechnung mit numerischer Differentiation vergleicht.
Explodierende Gradienten
Jetzt erstellen wir eine Visualisierung, die veranschaulicht, wie sich die Gradienten über den zeitlichen Verlauf entwickeln, um ein Verständnis von explodierenden Gradienten zu erlangen. Im Anschluss werden wir das Problem der explodierenden Gradienten beheben, indem wir eine Limitierung der Gradienten implementieren (Gradient Clipping).
LSTM in TensorFlow
Um es uns einfacher zu machen, wechseln wir nun zurück zu TensorFlow und implementieren die komplexere LSTM-Architektur inklusive dem Zellzustand und den Gattern.
Einfache Beispielaufgaben
Wir betrachten im Folgenden zwei einfache Beispielaufgaben: in der ersten Aufgabe soll das Netzwerk eine Sinuskurve mit zufälliger Frequenz und Phasenverschiebung extrapolieren. In der zweiten Aufgabe soll das Netzwerk eine Eingabesequenz memorieren. Wir werden die Fähigkeiten des einfachen RNN mit denen des LSTM-Netzes unter Betrachtung der beiden Aufgaben vergleichen.
Sprachmodellierung mit Hilfe von LSTM-Netzwerken
Als nächste Aufgabe wollen wir ein Sprachmodell trainieren, das auf Texten von Shakespeare basiert. Ziel der Übung ist es, ein Sprachmodell von Shakespeare zu lernen und dann mit dem erlernten Modell einen neuen Text zu erzeugen, der ähnliche Eigenschaften wie der Quelltext aufweist. Genauer gesagt, wird zu einer gegebenen Folge von Zeichen aus Shakespeares Texten, ein charakterbasiertes RNN-Modell trainiert, um das nächste Zeichen in der Folge vorherzusagen. Das Sprachmodell sagt die Wahrscheinlichkeit für jedes Wort einer Eingabefolge von Text vorher. Das vorhergesagte Wort wird dann im nächsten Zeitschritt als Eingabe in das Netzwerk eingespeist. Um dies zu implementieren, wird die TensorFlow-Bibliothek verwendet, um das LSTM-Netzwerk zu erstellen, das das Sprachmodell erlernt und dann zur Generierung eines neuen Textes verwendet.
Generierung von Bildbeschriftungen
Nun, da wir mit den zugrunde liegenden Prinzipien von RNNs vertraut sind, betrachten wir die Aufgabe der automatischen Bildbeschreibung (Image Captioning) mit Hilfe eines LSTMs. Image Captioning zielt darauf ab, eine aussagekräftige textuelle Beschreibung basierend auf dem Inhalt eines bestimmten Bildes zu erstellen. Um dies zu erreichen, werden wir die für RNNs erlernten Techniken anwenden, um bei jedem Zeitschritt Wörter basierend auf dem Bildinhalt und dem zuvor generierten Wort zu erzeugen. Die Bildmerkmale, die mit einem vortrainierten CNN extrahiert werden, werden im Rahmen der Übung bereitgestellt. Ziel dieser Aufgabe ist es, mit Hilfe der Tensorflow-Bibliothek ein LSTM-Netzwerk zu implementieren, das diese Bildmerkmale als Eingabe akzeptiert und Bildbeschreibungen für jedes der Bilder generiert.
Dieser Versuch zeigte die Verwendung von verschiedenen Varianten von rekurrenten Netzen, einerseits für einfache Beispielaufgaben, andererseits für ein realistischeres Problem, der Generierung von Bildbeschriftungen. Nach Erarbeitung dieses Versuchs sollte es nun möglich sein, einfache sequenzbasierte Aufgaben mit Hilfe von RNN zu lösen.
Sie verlassen die offizielle Website der Hochschule Trier