- Hochschule Trier
- Campus wählen
- Quicklinks
-
- English
Die Synthese und Ausgabe von Sprache eröffnet neue Möglichkeiten: Messwerte können hörbar gemacht, Statusmeldungen direkt ausgegeben oder ganze Assistenzfunktionen umgesetzt werden. Gerade bei Mikrocontrollern wie dem ESP8266 oder ESP32 stellt sich dabei jedoch die Frage, wie Sprachausgabe effizient realisiert werden kann, und wie wir mit dem Datenschutz umgehen.
Ziele:
In diesem Tutorial lernen wir zwei unterschiedliche Ansätze kennen. Zum einen die Nutzung eines Cloud-Dienstes wie Google Text-to-Speech (TTS), der besonders natürliche Stimmen liefert, jedoch eine Internetverbindung benötigt. Zum anderen betrachten wir eine vollständig lokale Lösung mit einem kompakten Sprachsynthese-Modell, das direkt auf dem Mikrocontroller läuft und ohne Netzwerk auskommt. Beide Verfahren haben ihre eigenen Stärken und Einsatzgebiete, die wir im Verlauf des Tutorials gegenüberstellen. Abschließend setzen wir das Gelernte praktisch um und entwickeln eine sprechende Temperaturanzeige, die Messwerte automatisch erfasst und akustisch ausgibt.
Transparenzhinweis: Die Sprachausgabe in diesem Beispiel wird mit Google Text‑to‑Speech (TTS) als KI‑basierte Sprachsynthese erstellt. Es handelt sich um eine synthetische Sprachausgabe, nicht um eine natürliche Personenstimme.
Cloudbasierte Sprachausgabe
Dabei wird der zu sprechende Text vom Mikrocontroller über eine Netzwerkverbindung an einen externen Dienst gesendet. Ein typisches Beispiel ist die Google TTS API. Der Dienst verarbeitet den Text mithilfe leistungsfähiger neuronaler Netze und generiert eine MP3 Audiodatei, die anschließend an das Gerät zurückgesendet, dort gespeichert und dann abgespielt wird. Im Falle der Google-API wird folgende REST-API genutzt: “http://translate.google.com/translate_tts?ie=UTF-8&"q=Mein gewünschter Text&tl=+lang+"&client=tw-ob".
Vorteile cloudbasierter Lösungen:
Nachteile cloudbasierter Lösungen:
Lokale Sprachmodelle
Dabei wird der Text direkt auf dem Mikrocontroller verarbeitet und die Sprache generiert. Bibliotheken wie ESP8266SAM basieren auf klassischen Sprachsyntheseverfahren (z. B. Formant-Synthese), die vergleichsweise wenig Rechenleistung benötigen.
Vorteile lokaler Lösungen (EDGE):
Nachteile lokaler Lösungen:
Unsere Audiosignale werden über den internen DAC des ESP32 generiert. Dieser Digital-Analog-Converter hat 8 Bit, d.h. es gibt 256 verschiedene Spannungspegel am Ausgang. Über einen kleinen Verstärker gehen die Signale normalerweise direkt an den internen Buzzer. Dieser kann Analogsignale allerdings nur unzureichend wiedergeben. Deshalb schließen wir über die vorhandenen Lötkontakte einen externen Lautsprecher an. (Achtung: Keinesfalls die Rechtecksignale der Buzzer-Blöckchen auf den Lautsprecher geben. Das Signal kann sehr laut werden, die Ohren schädigen und den Lautsprecher zerstören). Die Blöckchen für die Sprachausgabe finden wir im Baukasten “BT/Audio”.




Bitte beachten Sie: Sobald Sie sich das Video ansehen, werden Informationen darüber an VCRP/Panopto übermittelt. Weitere Informationen dazu finden Sie hier.
Anwendung: sprachgestützte Temperaturausgabe
Wie cool wäre es, wenn unser Thermometer sprechen könnte?
Solch eine Anwendung lässt sich mit wenig Aufwand realisieren. Wir messen die Temperatur, runden auf eine Nachkommastelle und übergeben den Messwert zusammen mit etwas Erklärungstext an die Sprachausgabe. Über den Drehencoder lässt sogar sich die Lautstärke anpassen. Die deutsche Version spricht über das cloudgestützte Text to Speech - API von Google, die englische Version nutzt die energieeffizientere lokale Sprachsynthese. Dabei lernt Google natürlich die Temperaturen in unserem Raum kennen - aus Datenschutzgründen also mit Bedacht einzusetzen.
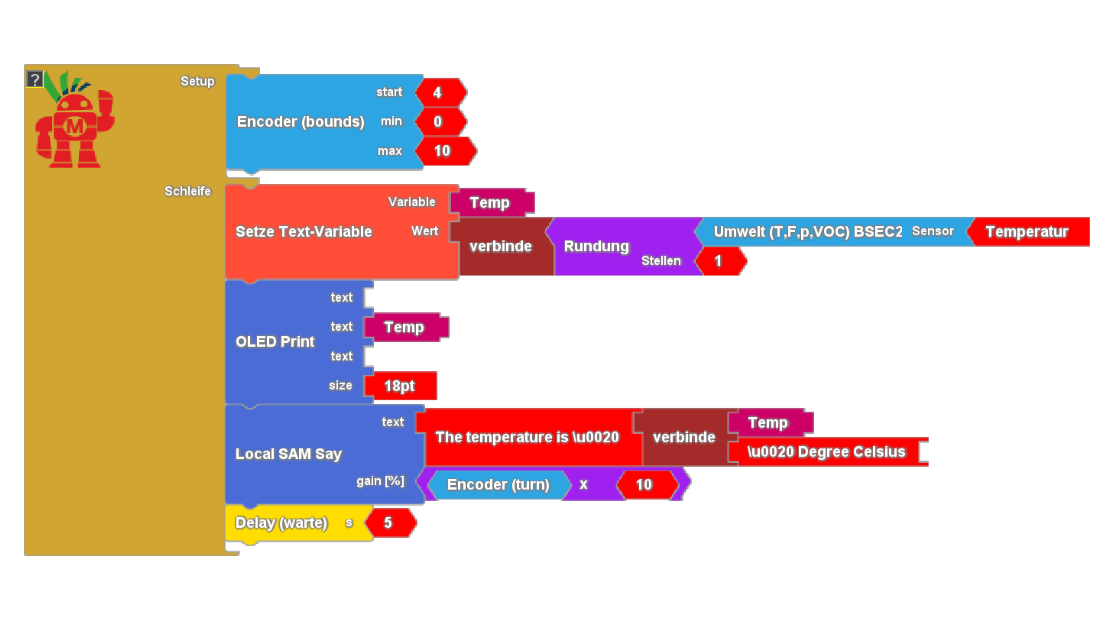
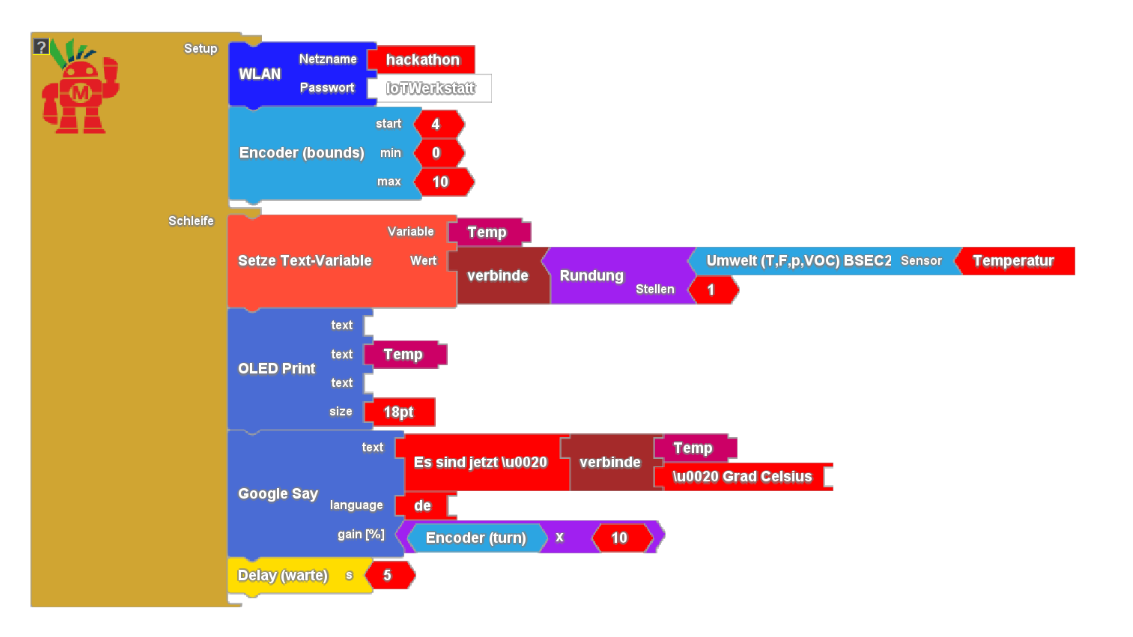

Bitte beachten Sie: Sobald Sie sich das Video ansehen, werden Informationen darüber an VCRP/Panopto übermittelt. Weitere Informationen dazu finden Sie hier.

Bitte beachten Sie: Sobald Sie sich das Video ansehen, werden Informationen darüber an VCRP/Panopto übermittelt. Weitere Informationen dazu finden Sie hier.
Die Wahl des geeigneten Verfahrens hängt stark vom Anwendungskontext ab:
Sie verlassen die offizielle Website der Hochschule Trier