- Hochschule Trier
- Campus wählen
- Quicklinks
-
- English

Künstliche Intelligenz ist allgegenwärtig, aber oft schwer zu durchschauen. Unsere Blaupause öffnet diese „Black-Box“ anhand eines einfachen Beispiels einer KI, die gute von schlechten Äpfeln unterscheiden soll. Mit den EDGE-AI-Blöcken der IoT2-Werkstatt läuft KI direkt auf dem Mikrocontroller – transparent, ohne Cloud und sehr energieeffizient. Wir nutzen dabei einen Algorithmus des überwachten Lernens: Die KI bekommt Beispiele mit bekannten Merkmalen und Ergebnissen. Daraus entsteht ein kleines Programm zum maschinellen Lernen, welches später selbst entscheidet, welcher Apfel wahrscheinlich gut schmecken wird. In der Trainingsphase zeigen wir der KI verschiedene Äpfel: rote, gute und grüne, saure Äpfel und speichern diese in einer Lernstichprobe. So lernt der Algorithmus die Unterschiede kennen. Kommt in der Anwendungsphase ein neuer, unbekannter Apfel, sucht die KI den ähnlichsten aus den Beispielen und sagt: „wahrscheinlich gut“ oder „eher sauer“. Genau wie wir im Supermarkt: Wir greifen zu Äpfeln, die wir von früher als lecker kennen. So entsteht eine erste, anfassbare KI, die man direkt mit echten Äpfeln testen kann.
Unsere Ziele:
Am Ende steht eine Lösung, die durchaus auch im professionellen Umfeld der Lebensmittelindustrie Anwendung findet.
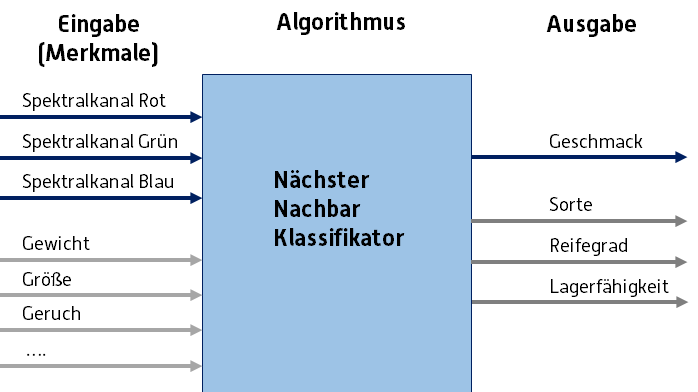
Transparenzhinweis: Dieses Beispiel verwendet einen selbstgebauten Klassifikator nach dem Prinzip „Nächster Nachbar“ (Nearest Neighbour). Klassifikationen werden automatisch auf Basis der Eingabedaten erzeugt.

Bitte beachten Sie: Sobald Sie sich das Video ansehen, werden Informationen darüber an Youtube/Google übermittelt. Weitere Informationen dazu finden Sie unter Google Privacy.
Um den Algorithmus anfassbar zu gestalten, benötigen wir zuerst eine Online-Erfassung der Merkmale. Dies können z. B. das Gewicht, der Durchmesser oder die Farbe sein. In unserem Fall kommt ein RGB-Farbsensor APDS-9960 (Alternative) zum Einsatz. Dieser ermittelt die Farbe unseres Apfels, indem er sie in die drei Spektralkanäle Rot (R), Grün (G) und Blau (B) zerlegt. Die Intensität dieser drei Kanäle sind also die Merkmale unseres Apfels. Natürlich leuchtet der Apfel nicht von selbst, sondern wir benötigen Umgebungslicht zur Messung. Hier ist auf konstante Lichtverhältnisse zu achten (oder eine weiße LED zur Messfeldbeleuchtung zu integrieren, s.u.).
Als User-Interface zur Bedienung und Eingabe der Eigenschaften nutzen wir die CharliePlex LED Matrix oder ein OLED-Display und einen Drehencoder (z.B. diesen).

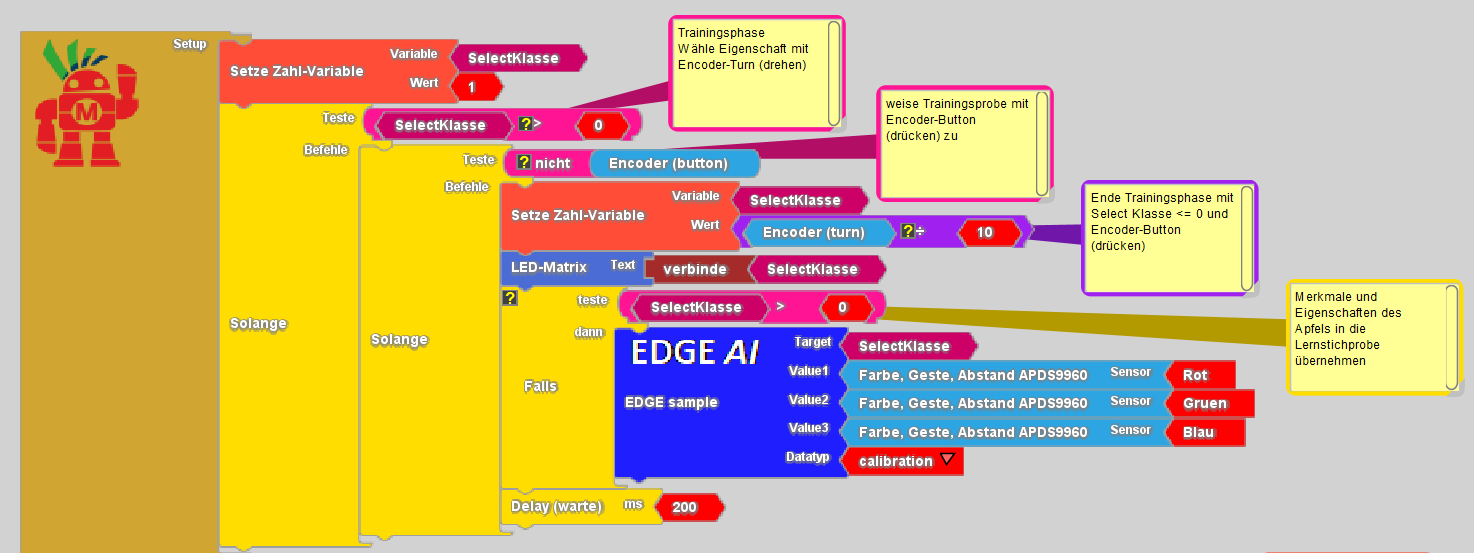
In der Trainingsphase erfassen wir für jeden Apfel seine Farbe und den zugehörigen Geschmack. Dazu halten wir den Apfel vor den Sensor und wählen mit dem Encoder eine Geschmacksklasse aus. Diese wird auf der LED-Matrix angezeigt und beim Tastendruck gespeichert: drei Farbwerte + eine Geschmacksnote (1 = lecker, 6 = sauer).
Diese Lernstichprobe wird anschließend in der Anwendungsphase genutzt, um die Äpfel nach ihrem Geschmack zu klassifizieren. Dabei ist:
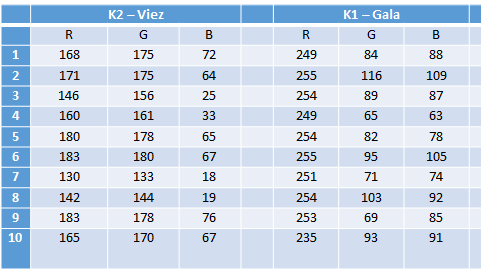
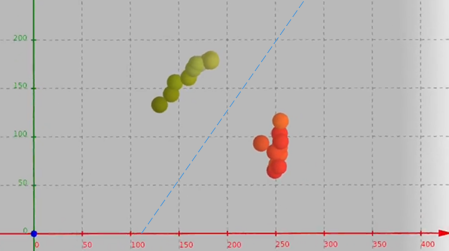
Wir vergeben für alle Äpfel der Lernstichprobe eine Geschmacksbeurteilung. Damit erweitern wir unser Datenfeld um weitere Elemente. Die Daten der n Elemente der Lernstichprobe können wir nun – etwa mit Geogebra 3D – visualisieren.


Bitte beachten Sie: Sobald Sie sich das Video ansehen, werden Informationen darüber an Youtube/Google übermittelt. Weitere Informationen dazu finden Sie unter Google Privacy.
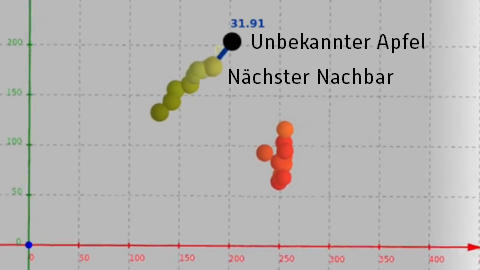
In der Anwendungsphase können wir die Eigenschaften (Geschmack) eines neuen, unbekannten Bewerbers bzw. Apfels prognostizieren. Hierzu nutzen wir einen sogenannten Nächste-Nachbarn-Klassifikator. Dieser entscheidet anhand unserer Trainingsdaten und den aktuellen Merkmalen, ob ein Apfel schmeckt oder nicht. Der Algorithmus ist sehr einfach, wir brauchen nur im Merkmalsraum zu schauen, welcher Apfel der Trainingsstichprobe unserem Apfel am nächsten kommt und schließen dann von diesem nächsten Nachbarn direkt auf die Eigenschaften des unbekannten Apfels. Optisch ist uns das sofort klar, mathematisch können wir das als euklidischen Abstand im Raum der Merkmalsvektoren bestimmen.



Bitte beachten Sie: Sobald Sie sich das Video ansehen, werden Informationen darüber an Youtube/Google übermittelt. Weitere Informationen dazu finden Sie unter Google Privacy.
Wenn wir nur grüne Viezäpfel im Training haben, hält die KI jeden grünen Apfel für sauer. Ein Golden Delicious hätte also keine Chance - die KI benachteiligt ihn, weil die Daten einseitig sind (sogenannte rassistische KI).
Lösung: Trainingsdaten vielfältig wählen.
Erweiterungen
Grüner Apfel ist nicht gleich grüner Apfel → mehr Merkmale nötig, z. B. Größe über Waage oder Abstandssensor.
RGB-Sensor kann mit eigener Beleuchtung verbessert werden (3D-Druck-Gehäuse vorhanden). Eine Anleitung dazu gibt es hier (Quelle IP-Projekt: S. Sohrabi, A. Harwardt).
EDGE-KI ist universell: Tauscht man RGB gegen den VOC-Sensor (BME680), kann die KI sogar Gerüche klassifizieren – wie im „künstliche Nase“-COSY-Projekt.
Unser Nachteil: Die Lernstichprobe geht bei Neustart verloren – in „echten“ Anwendungen würde man sie speichern.
Fortgeschrittene KI
Für kompliziertere Fälle (nicht linear trennbar) nutzt man Profiverfahren wie SVMs oder Neuronale Netze. Diese laufen heute sogar auf kleinen Geräten – z. B. über die EDGE-Impulse Cloud, für die in der IoT2-Werkstatt eigene Blöcke existieren.
Natürlich stehen wir dann vor dem Problem, einen wohlschmeckenden grünen Apfel von einem ungenießbaren grünen Viezapfel zu unterscheiden. Ein wichtiges Kriterium ist sicher die Größe. Dazu benötigen wir einen weiteren Sensor, vielleicht eine Waage oder eine Abstandsmessung zur Durchmesserbestimmung. Da unser Ardublock nur drei Merkmale gestattet, würden wir dann den blauen RGB-Kanal ersetzen.
Um die Farberkennung zu verbessern, kann der RGB-Sensor mit einer eigenen Beleuchtung ausgestattet werden. Eine Anleitung findet sich hier. Die Druckdatei für das Gehäuse hier. (Quelle IP-Projekt: S. Sohrabi, A. Harwardt).
Unser EDGE-KI Block sehr universell. Ersetzen wir die RGB-Kanäle durch den VOC Sensor des Octopus (BME 680), so können wir z.B. Getränke am Geruch erkennen. Siehe künstliche Nase im COSY-Projekt. Der einzige Nachteil, wir müssen bei jedem Neustart die Lernstichprobe erneut aufbauen, d.h. die Trainingsphase durchlaufen. Im Falle einer realen Anwendung würde man dies allerdings nur einmalig durchführen und das Datenfeld dann speichern.
Oben haben wir gesehen, dass sich rote und grüne Äpfel im 2D-Merkmalsraum einfach über eine Gerade (also linear) trennen lassen. Im Profibereich finden häufig leistungsfähigere Klassifikatoren wie z. B. die Support Vector Machine oder künstliche neuronale Netze ihren Einsatz, die auch nicht linear trennbare Klassen separieren. Diese lassen sich in einer EDGE-Variante auch auf eingebetteten Systemen nutzen. Hierzu sei auf die Cloud-Anwendung EDGE-Impulse verwiesen, zu deren Unterstützung es weitere Blöckchen im KI-Baukasten der IoT2-Werkstatt gibt.
Sie verlassen die offizielle Website der Hochschule Trier